
Suppose again that our random experiment is to perform a sequence of Bernoulli trials \(\bs
Let \( N = \min\
Since \( N \) and \( M \) differ by a constant, the properties of their distributions are very similar. Nonetheless, there are applications where it more natural to use one rather than the other, and in the literature, the term geometric distribution can refer to either. In this section, we will concentrate on the distribution of \( N \), pausing occasionally to summarize the corresponding results for \( M \).
= 1\]
A priori, we might have thought it possible to have \(N = \infty\) with positive probability; that is, we might have thought that we could run Bernoulli trials forever without ever seeing a success. However, we now know this cannot happen when the success parameter \(p\) is positive.
The probability density function of \(M\) is given by \(\P(M = n) = p (1 - p)^n\) for \( n \in \N\).In the negative binomial experiment, set \(k = 1\) to get the geometric distribution on \(\N_+\). Vary \(p\) with the scroll bar and note the shape and location of the probability density function. For selected values of \(p\), run the simulation 1000 times and compare the relative frequency function to the probability density function.
Note that the probability density functions of \( N \) and \( M \) are decreasing, and hence have modes at 1 and 0, respectively. The geometric form of the probability density functions also explains the term geometric distribution.
Suppose that \( T \) is a random variable taking values in \( \N_+ \). Recall that the ordinary distribution function of \( T \) is the function \( n \mapsto \P(T \le n) \). In this section, the complementary function \( n \mapsto \P(T \gt n) \) will play a fundamental role. We will refer to this function as the of \( T \). Of course both functions completely determine the distribution of \( T \). Suppose again that \( N \) has the geometric distribution on \( \N_+ \) with success parameter \( p \in (0, 1] \).
\( N \) has right distribution function \( G \) given by \(G(n) = (1 - p)^n\) for \(n \in \N\). Proof from Bernoulli trials Note that \(\ = (1 - p)^n \]
From the last result, it follows that the ordinary (left) distribution function of \(N\) is given by \[ F(n) = 1 - (1 - p)^n, \quad n \in \N \] We will now explore another characterization known as the .
For \( m \in \N \), the conditional distribution of \(N - m\) given \(N \gt m\) is the same as the distribution of \(N\). That is, \[\P(N \gt n + m \mid N \gt m) = \P(N \gt n); \quad m, \, n \in \N\] Proof From the result above and the definition of conditional probability, \[ \P(N \gt n + m \mid N \gt m) = \frac<\P(N \gt n + m)> <\P(N \gt m)>= \frac<(1 - p)^
Thus, if the first success has not occurred by trial number \(m\), then the remaining number of trials needed to achieve the first success has the same distribution as the trial number of the first success in a fresh sequence of Bernoulli trials. In short, Bernoulli trials have no memory. This fact has implications for a gambler betting on Bernoulli trials (such as in the casino games roulette or craps). No betting strategy based on observations of past outcomes of the trials can possibly help the gambler.
Conversely, if \(T\) is a random variable taking values in \(\N_+\) that satisfies the memoryless property, then \(T\) has a geometric distribution. Proof Let \(G(n) = \P(T \gt n)\) for \(n \in \N\). The memoryless property and the definition of conditional probability imply that \(G(m + n) = G(m) G(n)\) for \(m, \; n \in \N\). Note that this is the for \(G\). It follows that \(G(n) = G^n(1)\) for \(n \in \N\). Hence \(T\) has the geometric distribution with parameter \(p = 1 - G(1)\).
Suppose again that \(N\) is the trial number of the first success in a sequence of Bernoulli trials, so that \(N\) has the geometric distribution on \(\N_+\) with parameter \(p \in (0, 1]\). The mean and variance of \(N\) can be computed in several different ways.
\(\E(N) = \frac<1>\) Proof from the density function Using the derivative of the geometric series, \begin \E(N) &= \sum_^\infty n p (1 - p)^ = p \sum_^\infty n (1 - p)^ \\ &= p \sum_^\infty - \frac(1 - p)^n = - p \frac \sum_^\infty (1 - p)^n \\ &= -p \frac \frac<1>
= -p \left(-\frac<1>\right) = \frac<1>
\end Proof from the right distribution function Recall that since \( N \) takes positive integer values, its expected value can be computed as the sum of the right distribution function. Hence \[ \E(N) = \sum_^\infty \P(N \gt n) = \sum_^\infty (1 - p)^n = \frac<1>
\] Proof from Bernoulli trials We condition on the first trial \( X_1 \): If \( X_1 = 1 \) then \( N = 1 \) and hence \( \E(N \mid X_1 = 1) = 1 \). If \( X_1 = 0 \) (equivalently \( N \gt 1) \) then by the memoryless property, \( N - 1 \) has the same distribution as \( N \). Hence \( \E(N \mid X_1 = 0) = 1 + \E(N) \). In short \[ \E(N \mid X_1) = 1 + (1 - X_1) \E(N) \] It follows that \[ \E(N) = \E\left[\E(N \mid X_1)\right] = 1 + (1 - p) \E(N)\] Solving gives \( \E(N) = \frac<1>
\).
This result makes intuitive sense. In a sequence of Bernoulli trials with success parameter \( p \) we would expect to wait \( 1/p \) trials for the first success.
\( \var(N) = \frac<1 - p> \) Direct proof We first compute \( \E\left[N(N - 1)\right] \). This is an example of a factorial moment, and we will compute the general factorial moments below. Using derivatives of the geometric series again, \begin \E\left[N(N - 1)\right] & = \sum_^\infty n (n - 1) p (1 - p)^ = p (1 - p) \sum_^\infty n(n - 1) (1 - p)^ \\ & = p (1 - p) \frac \sum_^\infty (1 - p)^n = p (1 - p) \frac \frac<1>= p (1 - p) \frac = 2 \frac<1 - p> \end Since \( \E(N) = \frac<1>
\), it follows that \( \E\left(N^2\right) = \frac \) and hence \( \var(N) = \frac<1 - p> \) Proof from Bernoulli trials Recall that \[ \E(N \mid X_1) = 1 + (1 - X_1) \E(N) = 1 + \frac<1>
(1 - X_1) \] and by the same reasoning, \( \var(N \mid X_1) = (1 - X_1) \var(N) \). Hence \[ \var(N) = \var\left[\E(N \mid X_1)\right] + \E\left[\var(N \mid X_1)\right] = \frac<1> p(1 - p) + (1 - p) \var(N) \] Solving gives \( \var(N) = \frac<1 - p> \).
Note that \( \var(N) = 0 \) if \( p = 1 \), hardly surprising since \( N \) is deterministic (taking just the value 1) in this case. At the other extreme, \( \var(N) \uparrow \infty \) as \( p \downarrow 0 \).
In the negative binomial experiment, set \(k = 1\) to get the geometric distribution. Vary \(p\) with the scroll bar and note the location and size of the mean\(\pm\)standard deviation bar. For selected values of \(p\), run the simulation 1000 times and compare the sample mean and standard deviation to the distribution mean and standard deviation.
the probability generating function \( P \) of \(N\) is given by \[ P(t) = \E\left(t^N\right) = \frac
, \quad \left|t\right| \lt \frac \] Proof This result follows from yet another application of geometric series: \[ \E\left(t^N\right) = \sum_^\infty t^n p (1 - p)^ = p t \sum_^\infty \left[t (1 - p)\right]^ = \frac
, \quad \left|(1 - p) t\right| \lt 1 \]
Recall again that for \( x \in \R \) and \( k \in \N \), the of \( x \) of order \( k \) is \( x^ = x (x - 1) \cdots (x - k + 1) \). If \( X \) is a random variable, then \( \E\left[X^\right] \) is the of \( X \) of order \( k \).
The factorial moments of \(N\) are given by \[ \E\left[N^\right] = k! \frac<(1 - p)^>, \quad k \in \N_+ \] Proof from geometric series Using derivatives of geometric series again, \begin \E\left[N^\right] & = \sum_^\infty n^ p (1 - p)^ = p (1 - p)^ \sum_^\infty n^ (1 - p)^ \\ & = p (1 - p)^ (-1)^k \frac \sum_^\infty (1 - p)^n = p (1 - p)^ (-1)^k \frac \frac= k! \frac<(1 - p)^> \end Proof from the generating function Recall that \(\E\left[N^\right] = P^(1)\) where \(P\) is the probability generating function of \(N\). So the result follows from standard calculus.
The factorial moments can be used to find the moments of \(N\) about 0. The results then follow from the standard computational formulas for skewness and kurtosis.
Note that the geometric distribution is always positively skewed. Moreover, \( \skw(N) \to \infty \) and \( \kur(N) \to \infty \) as \( p \uparrow 1 \).
Suppose now that \(M = N - 1\), so that \(M\) (the number of failures before the first success) has the geometric distribution on \(\N\). Then
\)
\) for \(\left|t\right| \lt \frac\)
Of course, the fact that the variance, skewness, and kurtosis are unchanged follows easily, since \(N\) and \(M\) differ by a constant.
Let \(F\) denote the distribution function of \(N\), so that \(F(n) = 1 - (1 - p)^n\) for \(n \in \N\). Recall that \(F^(r) = \min \\) for \(r \in (0, 1)\) is the quantile function of \(N\).
The quantile function of \(N\) is \[ F^(r) = \left\lceil \frac<\ln(1 - r)><\ln(1 - p)>\right\rceil, \quad r \in (0, 1) \]
Of course, the quantile function, like the probability density function and the distribution function, completely determines the distribution of \(N\). Moreover, we can compute the median and quartiles to get measures of center and spread.
The first quartile, the median (or second quartile), and the third quartile are
Open the special distribution calculator, and select the geometric distribution and CDF view. Vary \( p \) and note the shape and location of the CDF/quantile function. For various values of \( p \), compute the median and the first and third quartiles.
Suppose that \(T\) is a random variable taking values in \(\N_+\), which we interpret as the first time that some event of interest occurs.
The function \( h \) given by \[ h(n) = \P(T = n \mid T \ge n) = \frac<\P(T = n)><\P(T \ge n)>, \quad n \in \N_+ \] is the of \(T\).
If \(T\) is interpreted as the (discrete) lifetime of a device, then \(h\) is a discrete version of the studied in reliability theory. However, in our usual formulation of Bernoulli trials, the event of interest is success rather than failure (or death), so we will simply use the term rate function to avoid confusion. The constant rate property characterizes the geometric distribution. As usual, let \(N\) denote the trial number of the first success in a sequence of Bernoulli trials with success parameter \(p \in (0, 1)\), so that \(N\) has the geometric distribution on \(\N_+\) with parameter \(p\).
\(N\) has constant rate \(p\).
From the results above, \( \P(N = n) = p (1 - p)^ \) and \( \P(N \ge n) = \P(N \gt n - 1) = (1 - p)^ \), so \( \P(N = n) \big/ \P(N \ge n) = p \) for \( n \in \N_+ \).
Conversely, if \(T\) has constant rate \(p \in (0, 1)\) then \(T\) has the geometric distrbution on \(\N_+\) with success parameter \(p\).
Let \(H(n) = \P(T \ge n)\) for \(n \in \N_+\). From the constant rate property, \(\P(T = n) = p \, H(n)\) for \(n \in \N_+\). Next note that \(\P(T = n) = H(n) - H(n + 1)\) for \(n \in \N_+\). Thus, \(H\) satisfies the recurrence relation \(H(n + 1) = (1 - p) \, H(n)\) for \(n \in \N_+\). Also \(H\) satisfies the initial condition \(H(1) = 1\). Solving the recurrence relation gives \(H(n) = (1 - p)^\) for \(n \in \N_+\).
Suppose again that \( \bs = (X_1, X_2, \ldots) \) is a sequence of Bernoulli trials with success parameter \( p \in (0, 1) \). For \( n \in \N_+ \), recall that \(Y_n = \sum_^n X_i\), the number of successes in the first \(n\) trials, has the binomial distribution with parameters \(n\) and \(p\). As before, \( N \) denotes the trial number of the first success.
Suppose that \( n \in \N_+ \). The conditional distribution of \(N\) given \(Y_n = 1\) is uniform on \(\\).
Proof from sampling
We showed in the last section that given \( Y_n = k \), the trial numbers of the successes form a random sample of size \( k \) chosen without replacement from \( \ \). This result is a simple corollary with \( k = 1 \)
For \( j \in \ \) \[ \P(N = j \mid Y_n = 1) = \frac<\P(N = j, Y_n = 1)> <\P(Y_n = 1)>= \frac <\P\left(Y_
Note that the conditional distribution does not depend on the success parameter \(p\). If we know that there is exactly one success in the first \(n\) trials, then the trial number of that success is equally likely to be any of the \(n\) possibilities.
Another connection between the geometric distribution and the uniform distribution is given below in the alternating coin tossing game: the conditional distribution of \( N \) given \( N \le n \) converges to the uniform distribution on \( \ \) as \( p \downarrow 0 \).
The on \( [0, \infty) \), named for Simeon Poisson, is a model for random points in continuous time. There are many deep and interesting connections between the Bernoulli trials process (which can be thought of as a model for random points in discrete time) and the Poisson process. These connections are explored in detail in the chapter on the Poisson process. In this section we just give the most famous and important result—the convergence of the geometric distribution to the exponential distribution. The geometric distribution, as we know, governs the time of the first random point in the Bernoulli trials process, while the exponential distribution governs the time of the first random point in the Poisson process.
For reference, the exponential distribution with rate parameter \( r \in (0, \infty) \) has distribution function \( F(x) = 1 - e^ \) for \( x \in [0, \infty) \). The mean of the exponential distribution is \( 1 / r \) and the variance is \( 1 / r^2 \). In addition, the moment generating function is \( s \mapsto \frac \) for \( s \gt r \).
For \( n \in \N_+ \), suppose that \( U_n \) has the geometric distribution on \( \N_+ \) with success parameter \( p_n \in (0, 1) \), where \( n p_n \to r \gt 0 \) as \( n \to \infty \). Then the distribution of \( U_n / n \) converges to the exponential distribution with parameter \( r \) as \( n \to \infty \).
Let \( F_n \) denote the CDF of \( U_n / n \). Then for \( x \in [0, \infty) \) \[ F_n(x) = \P\left(\frac \le x\right) = \P(U_n \le n x) = \P\left(U_n \le \lfloor n x \rfloor\right) = 1 - \left(1 - p_n\right)^ <\lfloor n x \rfloor>\] But by a famous limit from calculus, \( \left(1 - p_n\right)^n = \left(1 - \frac\right)^n \to e^ \) as \( n \to \infty \), and hence \( \left(1 - p_n\right)^ \to e^ \) as \( n \to \infty \). But by definition, \( \lfloor n x \rfloor \le n x \lt \lfloor n x \rfloor + 1\) or equivalently, \( n x - 1 \lt \lfloor n x \rfloor \le n x \) so it follows that \( \left(1 - p_n \right)^ <\lfloor n x \rfloor>\to e^ \) as \( n \to \infty \). Hence \( F_n(x) \to 1 - e^ \) as \( n \to \infty \), which is the CDF of the exponential distribution.
Note that the condition \( n p_n \to r \) as \( n \to \infty \) is the same condition required for the convergence of the binomial distribution to the Poisson that we studied in the last section.
The geometric distribution on \( \N \) is an infinitely divisible distribution and is a compound Poisson distribution. For the details, visit these individual sections and see the next section on the negative binomial distribution.
A standard, fair die is thrown until an ace occurs. Let \(N\) denote the number of throws. Find each of the following:
A type of missile has failure probability 0.02. Let \(N\) denote the number of launches before the first failure. Find each of the following:
A student takes a multiple choice test with 10 questions, each with 5 choices (only one correct). The student blindly guesses and gets one question correct. Find the probability that the correct question was one of the first 4.
Recall that an American roulette wheel has 38 slots: 18 are red, 18 are black, and 2 are green. Suppose that you observe red or green on 10 consecutive spins. Give the conditional distribution of the number of additional spins needed for black to occur.
Geometric with \(p = \frac\)
The game of roulette is studied in more detail in the chapter on Games of Chance.
In the negative binomial experiment, set \(k = 1\) to get the geometric distribution and set \(p = 0.3\). Run the experiment 1000 times. Compute the appropriate relative frequencies and empirically investigate the memoryless property \[ \P(V \gt 5 \mid V \gt 2) = \P(V \gt 3) \]
We will now explore a gambling situation, known as the , which leads to some famous and surprising results. Suppose that we are betting on a sequence of Bernoulli trials with success parameter \(p \in (0, 1)\). We can bet any amount of money on a trial at : if the trial results in success, we receive that amount, and if the trial results in failure, we must pay that amount. We will use the following strategy, known as a :
Let \( N \) denote the number of trials played, so that \( N \) has the geometric distribution with parameter \( p \), and let \( W \) denote our net winnings when we stop.
The first win occurs on trial \(N\), so the initial bet was doubled \(N - 1\) times. The net winnings are \[W = -c \sum_^ 2^i + c 2^ = c\left(1 - 2^ + 2^\right) = c\]
Thus, \(W\) is not random and \(W\) is independent of \(p\)! Since \(c\) is an arbitrary constant, it would appear that we have an ideal strategy. However, let us study the amount of money \(Z\) needed to play the strategy.
The expected amount of money needed for the martingale strategy is \[ \E(Z) = \begin \frac, & p \gt \frac \\ \infty, & p \le \frac \end \]
Thus, the strategy is fatally flawed when the trials are unfavorable and even when they are fair, since we need infinite expected capital to make the strategy work in these cases.
Compute \(\E(Z)\) explicitly if \(c = 100\) and \(p = 0.55\).
In the negative binomial experiment, set \(k = 1\). For each of the following values of \(p\), run the experiment 100 times. For each run compute \(Z\) (with \(c = 1\)). Find the average value of \(Z\) over the 100 runs:
For more information about gambling strategies, see the section on Red and Black. Martingales are studied in detail in a separate chapter.
A coin has probability of heads \(p \in (0, 1]\). There are \(n\) players who take turns tossing the coin in round-robin style: player 1 first, then player 2, continuing until player \(n\), then player 1 again, and so forth. The first player to toss heads wins the game.
Let \(N\) denote the number of the first toss that results in heads. Of course, \(N\) has the geometric distribution on \(\N_+\) with parameter \(p\). Additionally, let \(W\) denote the winner of the game; \(W\) takes values in the set \(\\). We are interested in the probability distribution of \(W\).
For \(i \in \\), \(W = i\) if and only if \(N = i + k n\) for some \(k \in \N\). That is, using modular arithmetic, \[ W = [(N - 1) \mod n] + 1 \]
The winning player \(W\) has probability density function \[ \P(W = i) = \frac
>, \quad i \in \ \]
This follows from the previous exercise and the geometric distribution of \(N\).
This result can be argued directly, using the memoryless property of the geometric distribution. In order for player \(i\) to win, the previous \(i - 1\) players must first all toss tails. Then, player \(i\) effectively becomes the first player in a new sequence of tosses. This result can be used to give another derivation of the probability density function in the previous exercise.
Note that \(\P(W = i)\) is a decreasing function of \(i \in \\). Not surprisingly, the lower the toss order the better for the player.
Explicitly compute the probability density function of \(W\) when the coin is fair (\(p = 1 / 2\)).
Note from the result above that \(W\) itself has a .
The distribution of \(W\) is the same as the conditional distribution of \(N\) given \(N \le n\): \[ \P(W = i) = \P(N = i \mid N \le n), \quad i \in \ \]
The following problems explore some limiting distributions related to the alternating coin-tossing game.
For fixed \(p \in (0, 1]\), the distribution of \(W\) converges to the geometric distribution with parameter \(p\) as \(n \uparrow \infty\).
For fixed \(n\), the distribution of \(W\) converges to the uniform distribution on \(\\) as \(p \downarrow 0\).
Players at the end of the tossing order should hope for a coin biased towards tails.
In the game of , we start with a specified number of players, each with a coin that has the same probability of heads. The players toss their coins at the same time. If there is an , that is a player with an outcome different than all of the other players, then the odd player is eliminated; otherwise no player is eliminated. In any event, the remaining players continue the game in the same manner. A slight technical problem arises with just two players, since different outcomes would make both players odd . So in this case, we might (arbitrarily) make the player with tails the odd man.
Suppose there are \(k \in \\) players and \(p \in [0, 1]\). In a single round, the probability of an odd man is \[r_k(p) = \begin 2 p (1 - p), & k = 2 \\ k p (1 - p)^ + k p^ (1 - p), & k \in \ \end\]
Let \(Y\) denote the number of heads. If \(k = 2\), the event that there is an odd man is \(\\). If \(k \ge 3\), the event that there is an odd man is \(\\>\). The result now follows since \(Y\) has a binomial distribution with parameters \( k \) and \( p \).
The graph of \(r_k\) is more interesting than you might think.
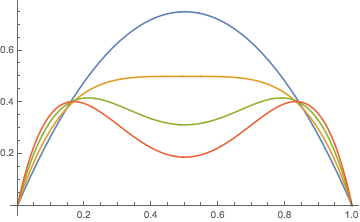
For \( k \in \ \), \(r_k\) has the following properties:
These properties are clear from the functional form of \( r_k(p) \). Note that \( r_k(p) = r_k(1 - p) \).
For \( k \in \ \), \(r_k\) has the following properties:
This follows by computing the first derivatives: \(r_2^\prime(p) = 2 (1 - 2 p)\), \(r_3^\prime(p) = 3 (1 - 2 p)\), \(r_4^\prime(p) = 4 (1 - 2 p)^3\), and the second derivatives: \( r_2^<\prime\prime>(p) = -4 \), \( r_3^<\prime\prime>(p) = - 6 \), \( r_4^<\prime\prime>(p) = -24 (1 - 2 p)^2 \).
For \( k \in \ \), \(r_k\) has the following properties:
Note that \(r_k(p) = s_k(p) + s_k(1 - p)\) where \(s_k(t) = k t^(1 - t)\) for \(t \in [0, 1]\). Also, \(p \mapsto s_k(p)\) is the dominant term when \(p \gt \frac\) while \(p \mapsto s_k(1 - p)\) is the dominant term when \(p \lt \frac\). A simple analysis of the derivative shows that \(s_k\) increases and then decreases, reaching its maximum at \((k - 1) / k\). Moreover, the maximum value is \(s_k\left[(k - 1) / k\right] = (1 - 1 / k)^ \to e^\) as \(k \to \infty\). Also, \( s_k \) is concave upward and then downward, wit inflection point at \( (k - 2) / k \).
Suppose \(p \in (0, 1)\), and let \(N_k\) denote the number of rounds until an odd man is eliminated, starting with \(k\) players. Then \(N_k\) has the geometric distribution on \(\N_+\) with parameter \(r_k(p)\). The mean and variance are
As we might expect, \(\mu_k(p) \to \infty\) and \(\sigma_k^2(p) \to \infty\) as \(k \to \infty\) for fixed \(p \in (0, 1)\). On the other hand, from the result above, \(\mu_k(p_k) \to e\) and \(\sigma_k^2(p_k) \to e^2 - e\) as \(k \to \infty\).
Suppose we start with \(k \in \\) players and \(p \in (0, 1)\). The number of rounds until a single player remains is \(M_k = \sum_^k N_j\) where \((N_2, N_3, \ldots, N_k)\) are independent and \(N_j\) has the geometric distribution on \(\N_+\) with parameter \(r_j(p)\). The mean and variance are
The form of \(M_k\) follows from the previous result: \(N_k\) is the number of rounds until the first player is eliminated. Then the game continues independently with \(k - 1\) players, so \(N_\) is the number of additional rounds until the second player is eliminated, and so forth. Parts (a) and (b) follow from the previous result and standard properties of expected value and variance.
Starting with \(k\) players and probability of heads \(p \in (0, 1)\), the total number of coin tosses is \(T_k = \sum_^k j N_j\). The mean and variance are
As before, the form of \(M_k\) follows from result above: \(N_k\) is the number of rounds until the first player is eliminated, and each these rounds has \(k\) tosses. Then the game continues independently with \(k - 1\) players, so \(N_\) is the number of additional rounds until the second player is eliminated with each round having \(k - 1\) tosses, and so forth. Parts (a) and (b) also follow from the result above and standard properties of expected value and variance.
Consider again a sequence of Bernoulli trials \( \bs X = (X_1, X_2, \ldots) \) with success parameter \( p \in (0, 1) \). Recall that the number of trials \( M \) before the first success (outcome 1) occurs has the geometric distribution on \( \N \) with parameter \( p \). A natural generalization is the random variable that gives the number of trials before a specific finite sequence of outcomes occurs for the first time. (Such a sequence is sometimes referred to as a from the \( \ \) or simply a ). In general, finding the distribution of this variable is a difficult problem, with the difficulty depending very much on the nature of the word. The problem of finding just the expected number of trials before a word occurs can be solved using powerful tools from the theory of renewal processes and from the theory of martingalges.
To set up the notation, let \( \bs x \) denote a finite bit string and let \( M_ \) denote the number of trials before \( \bs x \) occurs for the first time. Finally, let \( q = 1 - p \). Note that \( M_ \) takes values in \( \N \). In the following exercises, we will consider \( \bs x = 10 \), a success followed by a failure. As always, try to derive the results yourself before looking at the proofs.
The probability density function \( f_ \) of \( M_ \) is given as follows:
For \( n \in \N \), the event \(\ = n\>\) can only occur if there is an initial string of 0s of length \( k \in \ \) followed by a string of 1s of length \( n - k \) and then 1 on trial \( n + 1 \) and 0 on trial \( n + 2 \). Hence \[ f_(n) = \P(M_ = n) = \sum_^n q^k p^ p q, \quad n \in \N \] The stated result then follows from standard results on geometric series.
It's interesting to note that \( f \) is symmetric in \( p \) and \( q \), that is, symmetric about \( p = \frac \). It follows that the distribution function, probability generating function, expected value, and variance, which we consider below, are all also symmetric about \( p = \frac \). It's also interesting to note that \( f_(0) = f_(1) = p q \), and this is the largest value. So regardless of \( p \in (0, 1) \) the distribution is bimodal with modes 0 and 1.
The distribution function \( F_ \) of \( M_ \) is given as follows:
By definition, \(F_(n) = \sum_^n f_(k)\) for \( n \in \N \). The stated result then follows from the previous theorem, standard results on geometric series, and some algebra.
The probability generating function \( P_ \) of \( M_ \) is given as follows:
\left(\frac
- \frac\right), \quad |t| \lt \min \ \]
By definition, \[ P_(t) = \E\left(t^
The mean of \( M_ \) is given as follows:
Recall that \( \E(M_) = P^\prime_(1) \) so the stated result follows from calculus, using the previous theorem on the probability generating function. The mean can also be computed from the definition \( \E(M_) = \sum_^\infty n f_(n) \) using standard results from geometric series, but this method is more tedious.
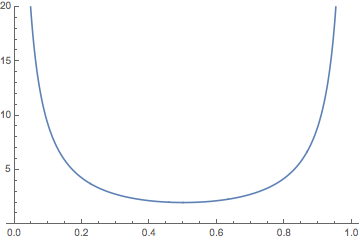
The graph of \( \E(M_) \) as a function of \( p \in (0, 1) \) is given below. It's not surprising that \( \E(M_) \to \infty \) as \( p \downarrow 0 \) and as \( p \uparrow 1 \), and that the minimum value occurs when \( p = \frac \).
The variance of \( M_ \) is given as follows:
Recall that \( P^<\prime \prime>_(1) = \E[M_(M_ - 1)] \), the second factorial moment, and so \[ \var(M_) = P^<\prime \prime>_(1) + P^\prime_(1) - [P^\prime_(1)]^2 \] The stated result then follows from calculus and the theorem above giving the probability generating function.
This page titled 11.3: The Geometric Distribution is shared under a CC BY 2.0 license and was authored, remixed, and/or curated by Kyle Siegrist (Random Services) via source content that was edited to the style and standards of the LibreTexts platform.